By Andrew Neumann, Omega’s VP of Technical Services and expert in IT operations & service delivery strategy
Anyone can close a ticket quickly. Fewer can resolve it accurately the first time.
In technical triage, speed is visible – accuracy is structural. When either is missing, businesses feel it through repeat disruptions, unnecessary escalations, or increased security exposure. The challenge isn’t choosing between speed and precision. It’s building an incident management process disciplined enough to deliver faster issue resolution without sacrificing accuracy, consistently and at scale.
The False Choice: Speed vs. Accuracy in Incident Management
Many service desks drift toward one of two extremes.
Some optimize for speed. Tickets close quickly. SLAs look strong. But recurring issues resurface because root causes weren’t fully addressed.
Others optimize for perfection. Every issue is over-analyzed. Engineers hesitate to act without complete certainty. Resolution times stretch, and productivity suffers.
Neither model works at scale.
When you’re managing thousands of incidents each month, speed without structure creates instability. In an MSSP environment – where infrastructure, security, compliance, and cloud systems are interconnected – a misdiagnosis can cascade. A rushed firewall change can introduce exposure. An incomplete permissions fix can create compliance gaps.
Technical triage isn’t just about resolving a ticket. It’s about protecting the broader environment while keeping the business moving. That requires structure, not reaction.
Triage and Prioritization: Structured Decision-Making in Real Time
A disciplined support triage process is not ticket routing. It is risk evaluation in real time.
The moment an issue is reported, three variables must be assessed:
- Impact – Who and what is affected?
- Urgency – Is business continuity at risk?
- Scope – Is the issue isolated or systemic?
That evaluation determines prioritization, issue escalation paths, and communication cadence within the broader technical support workflow. Without structure, speed becomes guesswork. With structure, speed becomes clarity.
Volume changes the equation.
A team handling a few hundred tickets per month can rely on informal knowledge and individual memory. An organization managing several thousand cannot. At scale, inconsistency compounds. Minor misjudgments repeat. Small prioritization gaps become systemic inefficiencies.
Not every ticket carries the same weight. A locked account and a ransomware indicator cannot follow the same response model. A single-device issue and a multi-site outage require entirely different escalation paths.
Effective prioritization considers operational disruption, security exposure, compliance risk, executive visibility, and the customer’s business and operational context. This is where many providers fall short. They apply generic severity models across every environment.
But environments differ. A healthcare organization protecting patient data or a financial services firm safeguarding investor information carries very different exposure than a distribution company managing warehouse logistics. Balancing speed and accuracy requires context – and context only exists when the service desk understands the business, not just the devices.
Process discipline isn’t bureaucracy. It’s what protects reliability as volume increases.
Escalation Discipline in Modern IT Support
Escalation has a reputation problem in IT. It’s often viewed as weakness.
In reality, structured escalation reflects operational maturity.
Clear thresholds must define when issues move within the customer support process from frontline support to engineering, security operations, or architecture. Waiting too long slows resolution and compounds impact. Escalating too quickly creates inefficiency and noise.
The balance lies in predefined criteria supported by experienced judgment.
When escalation triggers are clear, hesitation decreases and debate in high-pressure situations is minimized. The right expertise engages at the right time. That protects both speed and accuracy because decisions are guided by framework – not personality.
Root Cause Analysis and Long-Term Service Reliability
Closing a ticket is visible. Preventing recurrence builds trust.
Root cause analysis is where speed and accuracy converge.
If an email outage stems from a configuration conflict, restoring service is only the first step. The deeper work examines why the conflict occurred, what monitoring should have detected it, and whether preventive controls require adjustment.
If users repeatedly report VPN instability, resetting connections isn’t enough. Infrastructure health, authentication logs, network congestion, and policy configurations must be evaluated to determine systemic contributors.
This discipline matters even more in security events. False positives waste time. False negatives create exposure.
Structured post-incident review examines detection timing, response efficiency, communication clarity, and remediation completeness. Service reliability improves not through faster closure alone, but through embedded learning.
From Triage Data to Business Stability
When triage is disciplined, patterns emerge.
Across thousands of tickets each month, recurring issues begin to reveal structural gaps:
- Recurring device failures often signal hardware lifecycle planning gaps or operating systems approaching end of support.
- Repeated credential issues may indicate training gaps or weak identity and access policies. This becomes even more critical in environments relying on modern secure access frameworks.
- Frequent patch conflicts can expose weaknesses in testing and change management processes.
At scale, these patterns form a strategic dataset.
Our teams currently manage nearly 6,000 tickets per month. At that volume, service quality cannot depend on individual heroics. It depends on repeatable process.
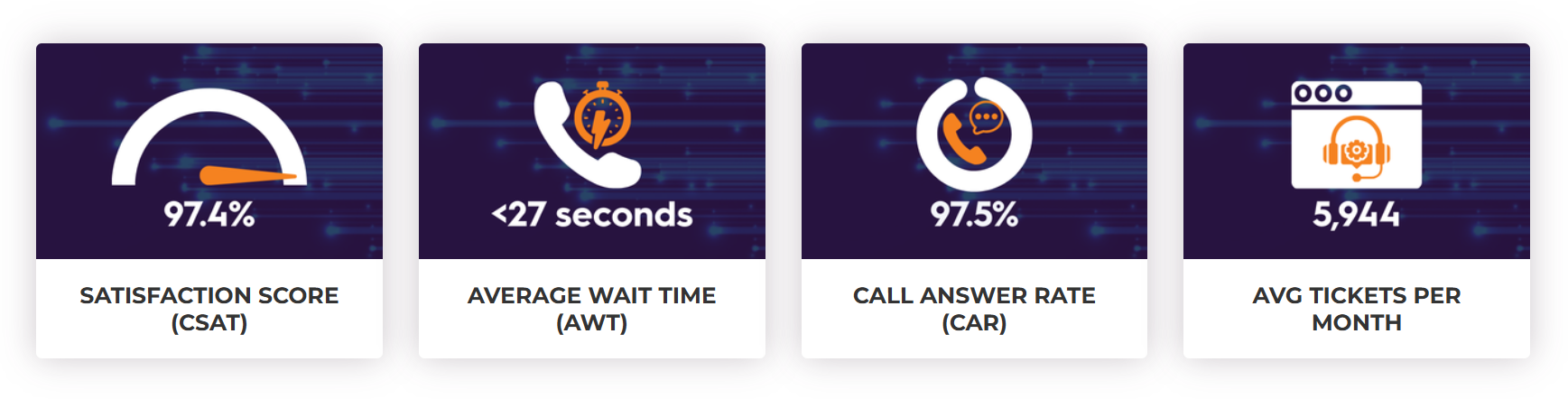
Managed IT support performance indicators such as a 97%+ customer satisfaction (CSAT) score, a 97% call answer rate, and sub-30-second average wait times are outcomes of that structure – not the objective itself. Without disciplined triage, those numbers would not be sustainable.
At scale, metrics validate process maturity; they don’t substitute for it.
Triage data feeds directly into infrastructure planning, security posture reviews, and Technical Business Reviews, informing decisions about architecture, risk mitigation, and long-term resilience.
Customers may never see that internal feedback loop. What they experience is stability: fewer repeat disruptions, clear ownership during incidents, and reduced security surprises.
They don’t have to wonder whether something was temporarily patched or fundamentally resolved.
They feel consistency.
Designing Incident Management for Security and Scale
Managed services today are inseparable from cybersecurity. Every support request exists within a broader threat landscape where misconfigurations, rushed fixes, or incomplete remediation can create downstream risk.
Balancing speed and accuracy isn’t just an operational philosophy. It’s a security imperative.
Speed builds confidence. Accuracy builds stability. Discipline builds both.
In managed services, there shouldn’t be a trade-off between responsiveness and precision – only an expectation of both.

 ABOUT THE AUTHOR
ABOUT THE AUTHOR
Andrew Neumann, Omega’s VP of Technical Services, leads the company’s managed IT support, escalation services, and service desk operations. With 20+ years of IT service delivery experience across multiple industries, he is passionate about streamlining processes to enhance the customer experience and drive strategic integration across Omega’s growing portfolio.
Connect with Andrew on LinkedIn.


